Quand la puissance rencontre l’efficacité : les SLMs redéfinissent l’intelligence artificielle, en version light.
Une révolution discrète mais impactante
Dans le monde spectaculaire de l’intelligence artificielle, les Grands Modèles de Langage, ou LLMs, ont longtemps capté l’attention. GPT-4, Claude, LLaMA 2 : autant de noms qui font rêver les data scientists... et grincer les dents des responsables IT lorsqu’ils voient la facture énergétique. Ces géants de la génération de texte sont performants, certes, mais ils exigent des ressources hors de portée pour beaucoup d’équipes.
C’est dans cet écart entre ambition technologique et réalisme opérationnel que les SLMs, ou Small Language Models, s’inscrivent. Moins gourmands, plus rapides à déployer, souvent open source, ils offrent une alternative sérieuse à ceux qui veulent intégrer l’IA sans hypothéquer leur parc machine.
SLMs vs LLMs : une affaire de gabarit
Les LLMs sont les bodybuilders de l’IA : impressionnants, musclés, et toujours en train de consommer d’énormes quantités de données et d’énergie. Les SLMs, à l’inverse, sont des athlètes agiles, entraînés pour des tâches spécifiques, avec un rapport performance/efficacité bien plus séduisant. Leurs paramètres se comptent en millions, parfois quelques milliards, loin des centaines de milliards qui définissent leurs grands frères.
Et si les LLMs savent tout faire – du code à la poésie –, les SLMs sont souvent spécialisés, formés pour exceller dans des usages concrets, comme répondre à des emails, classer des documents juridiques ou analyser des tickets de support technique.
Quelle infrastructure pour tester un SLM ?
C’est souvent la première barrière mentale : faut-il un GPU hors de prix pour jouer avec un modèle de langage ? Avec les SLMs, la réponse est souvent non.
Pour les modèles les plus légers, comme TinyLLaMA, DistilBERT ou Phi-2, un simple ordinateur portable équipé d’un processeur moderne (type Intel i7 ou AMD Ryzen 7) et de 16 Go de RAM suffit pour faire tourner des inférences de base. Le GPU n’est pas obligatoire, bien qu’un petit NVIDIA RTX (3050, 3060 ou équivalent) accélère considérablement les performances, surtout pour les cas d’usage en temps réel.
Pour des modèles un peu plus costauds – dans la tranche des 3 à 7 milliards de paramètres – une station de travail dotée d’un GPU dédié avec au moins 8 à 16 Go de VRAM est recommandée. Les configurations typiques des développeurs IA entrent ici en jeu : des machines équipées de RTX 3090, 4090, ou des serveurs cloud comme ceux proposés par Paperspace, Lambda Labs ou Google Colab Pro suffisent largement pour expérimenter, fine-tuner ou même déployer en local.
Ce qui change vraiment, c’est que vous n’avez plus besoin de réserver des instances à plusieurs milliers d’euros/mois. Un Raspberry Pi ne fera pas tourner Phi-2, mais votre PC gaming, oui.
Quel type d’usage pour une app ?
Si vous travaillez en entreprise, les SLMs peuvent devenir de véritables copilotes métiers. Par exemple, un modèle local peut servir d’assistant RH ou juridique, capable de relire des documents internes, trier des emails ou proposer des réponses types.
Côté IT, il devient un soutien précieux pour générer du code, automatiser des scripts ou documenter des processus. Intégré à un moteur de recherche interne, il peut jouer le rôle de guide intelligent dans une base documentaire, notamment avec une architecture de type RAG.
Enfin, son léger footprint lui permet d’être embarqué dans des outils du quotidien comme Notion, Obsidian, ou VSCode, où il interagit directement avec du contenu local pour enrichir l’expérience utilisateur sans jamais sortir du poste de travail.
Petit POC rapide
Si vous voulez tester en quelques minutes ce que vaut un petit modèle de langage, installez simplement Ollama.
https://ollama.com/
Une fois installé, ouvrez votre terminal et tapez ollama run mistral. En quelques secondes, vous avez la main sur un chatbot local fonctionnel, basé sur un Small Language Model.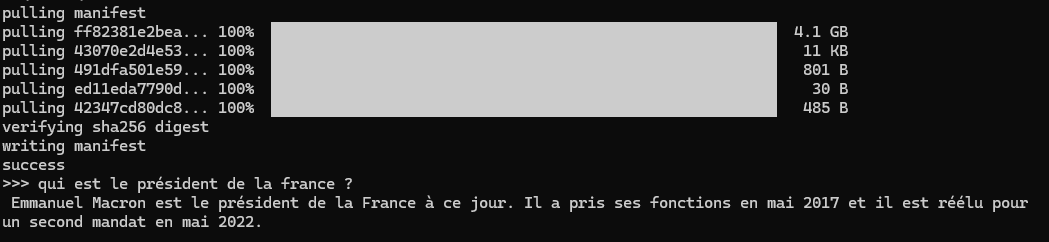
Mais attention, il a ses limites. Une question trop récente, et c’est la panique. Demandez-lui qui est le Premier ministre actuel et vous verrez qu'il risque de faire un retour dans le passé. Heureusement, avec un système de type RAG (Retrieval-Augmented Generation), il est tout à fait possible de lui fournir des données fraîches ou personnelles pour qu’il réponde avec plus de pertinence. Mais ça, c’est une autre histoire...
C'est possible de faire ça dans une page HTML bien entendu... Je vous propose un second POC dans Docker avec un petit serveur Node.js.
Voici le docker-compose.yml :
version: '3' services: ollama: image: ollama/ollama ports: - "11434:11434" volumes: - ollama:/root/.ollama open-webui: image: ghcr.io/open-webui/open-webui:main ports: - "3000:3000" environment: - OLLAMA_API_BASE_URL=http://ollama:11434 - WEBUI_SECRET_KEY=mon_super_secret - WEBUI_AUTH=False depends_on: - ollama volumes: - openwebui:/app/backend/data command: > sh -c "uvicorn open_webui.main:app --host 0.0.0.0 --port 3000" volumes: ollama: openwebui:
Voici maintenant le contenu du fichier server.js pour faire tourner un petit serveur Node.js qui fera office de proxy entre votre frontend HTML et Ollama :
const express = require('express'); const cors = require('cors'); const path = require('path'); const app = express(); app.use(cors()); app.use(express.json()); app.use(express.static(path.join(__dirname))); app.post('/api/generate', async (req, res) => { try { const response = await fetch('http://localhost:11434/api/generate', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(req.body) }); const data = await response.json(); res.json(data); } catch (err) { console.error(err); res.status(500).json({ error: 'Erreur côté proxy' }); } }); app.listen(4000, () => { console.log('Proxy + serveur statique dispo sur http://localhost:4000'); });
Et enfin, une page chat.html minimaliste qui interagit avec ce serveur :
<!DOCTYPE html> <html lang="fr"> <head> <meta charset="UTF-8"> <title>Mon Chat LLM</title> </head> <body> <h2>Parle à ton modèle local</h2> <input type="text" id="prompt" placeholder="Pose ta question..." /> <button onclick="sendPrompt()">Envoyer</button> <pre id="response" style="white-space: pre-wrap; margin-top: 20px;"></pre> <script> async function sendPrompt() { const prompt = document.getElementById('prompt').value; const resBox = document.getElementById('response'); resBox.textContent = 'Chargement...'; const res = await fetch("http://localhost:4000/api/generate", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ model: "mistral:latest", prompt: prompt, stream: false }) }); const data = await res.json(); resBox.textContent = data.response; } </script> </body> </html>
Puis dans le terminal :
docker-compose up -d
npm install node-fetch
ollama pull mistral
npm init -y
npm install express cors
Entrez dans le conteneur :
docker exec -it openwebui-ollama-1 /bin/sh
Et installez le modèle si besoin :
ollama pull mistral
Lancez ensuite votre serveur Node.js avec node server.js, puis ouvrez la page chat.html (pas besoin d'être sur le serveur).
Et là, la magie opère.
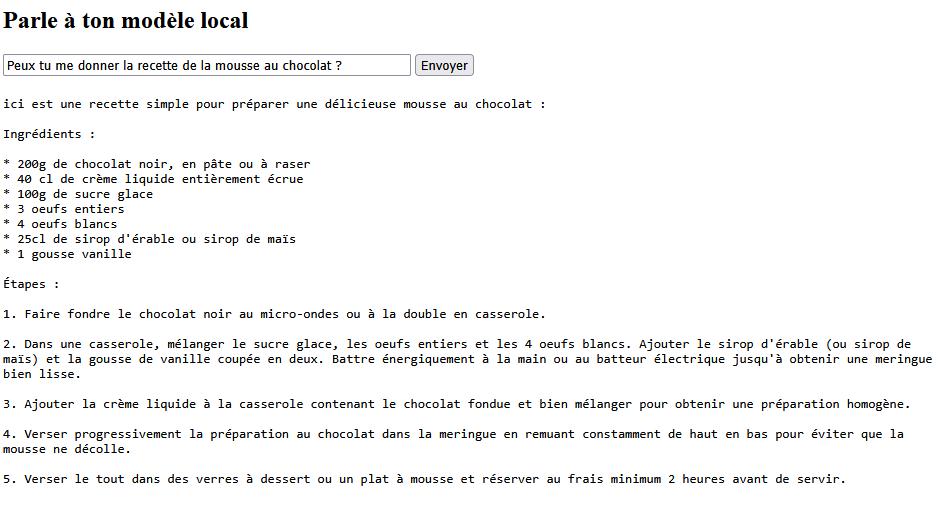
Alors attention, le délai de réponse peut prendre un peu de temps, car pour l'heure ce n'est pas votre carte graphique qui travaille, mais votre processeur. Bien entendu, ceci est juste un POC pour donner des idées de déploiement dans vos projets.
